Introduction¶
mirSTP is a computational tool for predicting transcription start sites (TSS) of human intergenic miRNAs at high resolution using GRO/PRO-seq data.
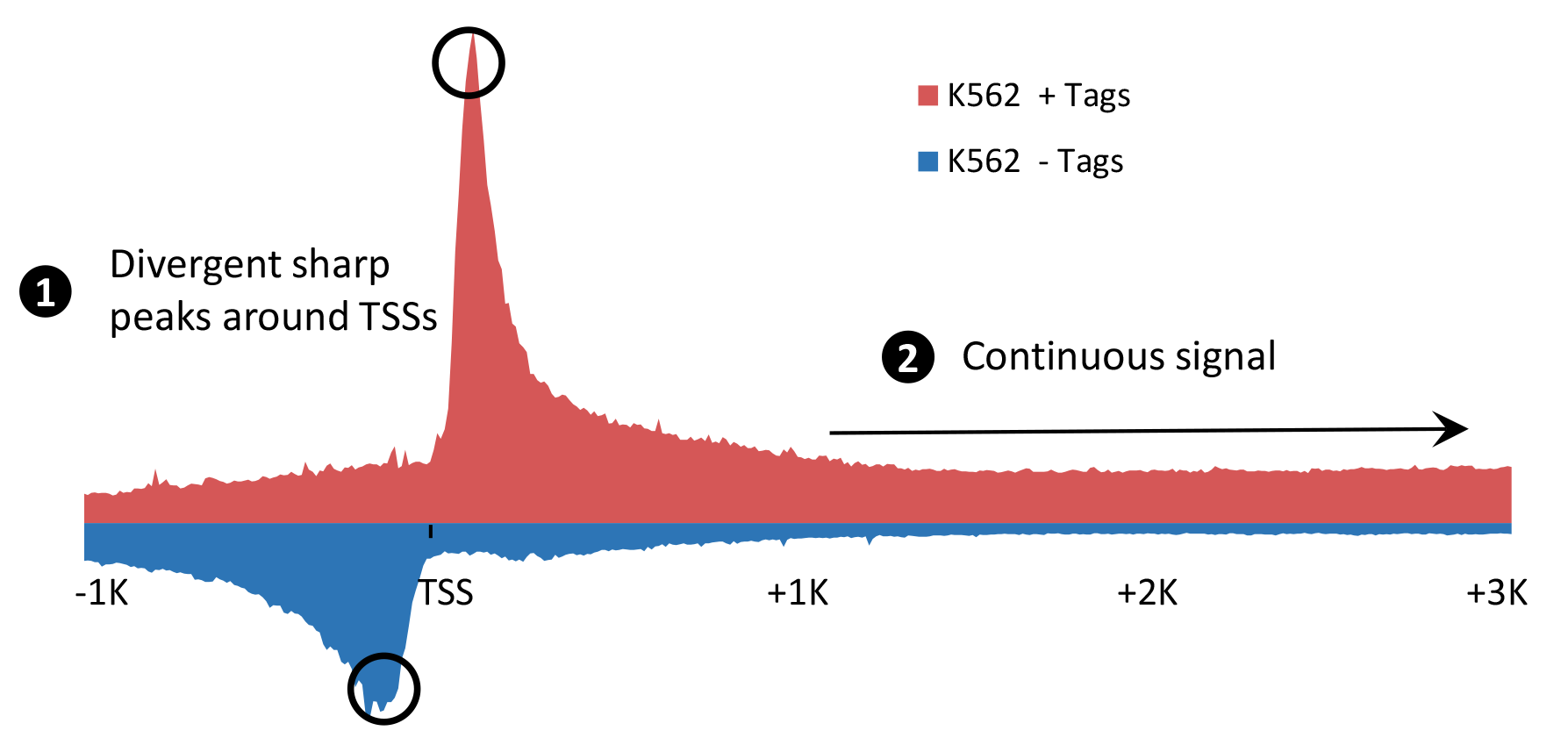
mirSTP takes advantage of two features of GRO/PRO-seq data to perform the prediction: 1) Divergent sharp peaks around transcription start sites; 2) continuous signal over active transcription regions.
Download¶
Software: mirSTP.zip
K562 GRO-seq data: K562_groseq.bam
Kasumi-1 PRO-seq data: Kasumi-1_proseq_1.bam, Kasumi-1_proseq_2.bam, Kasumi-1_proseq_3.bam, Kasumi-1_proseq_4.bam, Kasumi-1_proseq_5.bam, Kasumi-1_proseq_6.bam
OCI-LY1 PRO-seq data: OCI-LY1_proseq_1.bam, OCI-LY1_proseq_2.bam, OCI-LY1_proseq_3.bam
MV4-11 PRO-seq data: MV4-11_proseq_1.bam, MV4-11_proseq_2.bam
U936 PRO-seq data: U936_proseq_1.bam, U936_proseq_2.bam
Daudi PRO-seq data: Daudi_proseq.bam
Installation¶
1. Requirements: R and bedtools
Install R and bedtools (v2.24.0), and add /bin directory to your executable path.
- R: http://www.r-project.org/
- bedtools: https://github.com/arq5x/bedtools2/releases/ following the instructions.
2. Install mirSTP
unzip mirSTP.zip #Unzip the file
cd mirSTP/ #Change directories into the folder
chmod 755 bin/mirSTP #Change the mode of executable files
#Add mirSTP scripts to Shell searching path ($PATH). This step is optional.
#If your mirSTP is installed at /home/usrname/mirSTP
export PATH=/home/usrname/mirSTP/bin/:$PATH
Input and output¶
mirSTP takes an alignment of GRO/PRO-seq data and reports the predicted miRNA TSSs at stringent, medium, and relax cutoff levels.
1. Input
mirSTP takes hg19 alignment files in bed or bam format as input. Multiple samples should be given as a space-separated list.
2. Output
mirSTP tab-delimited text files including predicted TSSs for active intergenic miRNAs.
| **_mirSTP_stringent.txt: | predicted TSSs at the stringent cutoff level |
| **_mirSTP_medium.txt: | predicted TSSs at the medium cutoff level |
| **_mirSTP_relax.txt: | predicted TSSs at the relax cutoff level |
Each of the output file has following fields:
| Field | Description |
| miRNA | miRNA name |
| Chr | miRNA chromosome |
| TSS | Genomic coordinate of the predicted TSS |
| Strand | miRNA strand |
| Score_plus | Log likelihood score to estimate the sharp peaks at the sense strand |
| Score_minus | Log likelihood score to estimate the sharp peaks at the antisense strand |
| Pvalue_gb | p-value to estimate the activity of gene body |
| Num_5k | The minimum number of reads among the continuous 5kb window |
Usage¶
Usage: mirSTP -i bed/bam files -t technique -f format -o outputname
e.g: mirSTP -i K562_groseq.bam -t GRO -f bam -o K562
| -i [bed|bam file(s)] | required, hg19 read alignment files in bed (6 columns) or bam format, each file is separated by space |
| -t [GRO|PRO] | the technique to generate the data. (default: GRO) |
| -f [bed|bam] | alignment file format. (default: bam) |
| -o [string] | required, prefix of output file name |
| -h | help message |
Reference¶
Accurate identification of microRNA transcription start sites from nascent RNA sequencing. Nucleic Acids Res. 2017 Jul 27;45(13):e121. doi: 10.1093/nar/gkx318. PMID: 28460090
Contacts¶
- Contact Liu, Qi <qi.liu@vanderbilt.edu> or Wang, Jing <jing.wang.1@vanderbilt.edu> with any questions, comments or suggestions.